<xsl:key> / key() / IdKeyPattern
Contents
Functionality
The <xsl:key> element is a top-level element that can be
used to define a named index of nodes from the source XML tree(s). The
element has three attributes:
-
name- the name of the index -
match- a pattern that defines the nodeset we want indexed -
use- an expression that defines the value to be used as the index key value.
A named index can be accessed using either the key() function
or a KeyPattern. Both these methods address the index using its defined name
(the "name" attribute above) and a parameter defining one or more lookup
values for the index. The function or pattern returns a node set containing
all nodes in the index whose key value match the parameter's value(s):
<xsl:key name="book-author" match="book" use="author"/>
:
:
<xsl:for-each select="key('book-author', 'Mikhail Bulgakov')">
<xsl:value-of select="author"/>
<xsl:text>: </xsl:text>
<xsl:value-of select="author"/>
<xsl:text>
</xsl:text>
</xsl:for-each>
The KeyPattern can be used within an index definition to create unions and intersections of node sets:
<xsl:key name="cultcies" match="farmer | fisherman" use="name"/>
This could have been done using regular <xsl:for-each>
and <xsl:select> elements. However, if your stylesheet
accesses the same selection of nodes over and over again, the transformation
will be much more efficient using pre-indexed keys as shown above.
Implementation
Indexing
The AbstractTranslet class has a global hashtable that holds
an index for each named key in the stylesheet (hashing on the "name"
attribute of <xsl:key>). AbstractTranslet
has a couple of public methods for inserting and retrieving data from this
hashtable:
public void buildKeyIndex(String keyName, int nodeID, String value);
public KeyIndex KeyIndex getKeyIndex(String keyName);
The Key class compiles code that traverses the input DOM and
extracts nodes that match some given parameters (the "match"
attribute of the <xsl:key> element). A new element is
inserted into the named key's index. The nodes' DOM index and the value
translated from the "use" attribute of the
<xsl:key> element are stored in the new entry in the
index.
Something similar is done for indexing IDs. This index is generated from
the ID and IDREF fields in the input document's
DTD. This means that the code for generating this index cannot be generated
at compile-time, which again means that the code has to be generic enough
to handle all DTDs. The class that handles this is the
org.apache.xalan.xsltc.dom.DTDMonitor class. This class
implements the org.xml.sax.XMLReader and
org.xml.sax.DTDHandler interfaces. A client application using
the native API must instanciate a DTDMonitor and pass it to the
translet code - if, and only if, it wants IDs indexed (one can improve
performance by omitting this step). This is descrived in the
XSLTC Native API reference. The
DTDMonitor class will use the same indexing as the code
generated by the Key class. The index for ID's is called
"##id". We assume that no stylesheets will contain a key with this name.
The index itself is implemented in the
org.apache.xalan.xsltc.dom.KeyIndex class. The index has an
hashtable with all the values from the matching nodes (the part of the node
used to generate this value is the one specified in the "use"
attribute). For every matching value there is a bit-array (implemented in
the org.apache.xalan.xsltc.BitArray class), holding a list of
all node indexes for which this value gives a match:
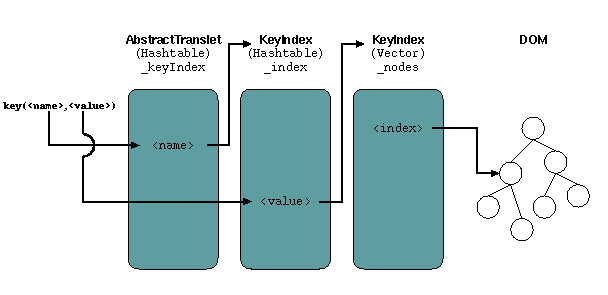
Figure 1: Indexing tables
The KeyIndex class implements the NodeIterator
interface, so that it can be returned directly by the implementation of the
key() function. This is how the index generated by
<xsl:key> and the node-set returned by the
key() and KeyPattern are tied together. You can see how this is
done in the translate() method of the KeyCall
class.
The key() function can be called in two ways:
key('key-name','value')
key('key-name','node-set')
The first parameter is always the name of the key. We use this value to lookup our index from the _keyIndexes hashtable in AbstractTranslet:
il.append(classGen.aloadThis());
_name.translate(classGen, methodGen);
il.append(new INVOKEVIRTUAL(getKeyIndex));
This compiles into a call to
AbstractTranslet.getKeyIndex(String name), and it leaves a
KeyIndex object on the stack. What we then need to do it to
initialise the KeyIndex to give us nodes with the requested
value. This is done by leaving the KeyIndex object on the stack
and pushing the "value" parameter to key(), before
calling lookup() on the index:
il.append(DUP); // duplicate the KeyIndex obejct before return
_value.translate(classGen, methodGen);
il.append(new INVOKEVIRTUAL(lookup));
This compiles into a call to KeyIndex.lookup(String value).
This will initialise the KeyIndex object to return nodes that
match the given value, so the KeyIndex object can be left on
the stack when we return. This because the KeyIndex object
implements the NodeIterator interface.
This matter is a bit more complex when the second parameter of
key() is a node-set. In this case we need to traverse the nodes
in the set and do a lookup for each node in the set. What I do is this:
-
construct a
KeyIndexobject that will hold the return node-set -
find the named
KeyIndexobject from the hashtable in AbstractTranslet - get an iterator for the node-set and do the folowing loop:
- get string value for current node
- do lookup in KeyIndex object for the named index
- merge the resulting node-set into the return node-set
- leave the return node-set on stack when done
Possible indexing improvements
The indexing implementation can be very, very memeory exhaustive as there
is one BitArray allocated for each value for every index. This
is particulary bad for the index used for IDs ('##id'), where a single value
should only map to one, single node. This means that a whole
BitArray is used just to contain one node. The
KeyIndex class should be updated to hold the first node for a
value in an Integer object, and then replace that with a
BitArray or a Vector only is a second node is
added to the value. Here is an outline for KeyIndex:
public void add(Object value, int node) {
Object container;
if ((container = (BitArray)_index.get(value)) == null) {
_index.put(value, new Integer(node));
}
else {
// Check if there is _one_ node for this value
if (container instanceof Integer) {
int first = ((Integer)container
_nodes = new BitArray(_arraySize);
_nodes.setMask(node & 0xff000000);
_nodes.setBit(first & 0x00ffffff);
_nodes.setBit(node & 0x00ffffff);
_index.put(value, _nodes);
}
// Otherwise add node to axisting bit array
else {
_nodex = (BitArray)container;
_nodes.setBit(node & 0x00ffffff);
}
}
}
Other methods inside the KeyIndex should be updated to
reflect this.
Id and Key patterns
As already mentioned, the challenge with the id() and
key() patterns is that they have no specific node type.
Patterns are normally grouped based on their pattern's "kernel" node type.
This is done in the org.apache.xalan.xsltc.compiler.Mode class.
The Mode class has a method, flatternAlaternative,
that does this grouping, and all templates with a common kernel node type
will be inserted into a "test sequence". A test sequence is a set templates
with the same kernel node type. The TestSeq class generates
code that will figure out which pattern, amongst several patterns with the
same kernel node type, that matches a certain node. This is used by the
Mode class when generating the applyTemplates
method in the translet. A test sequence is also generated for all templates
whose pattern does not have a kernel node type. This is the case for all
Id and KeyPatterns. This test sequence, if necessary, is put before the
big switch() in the applyTemplates() mehtod. This
test has to be done for every single node that is traversed, causing the
transformation to slow down siginificantly. This is why we do not
recommend using this type of patterns with XSLTC.