XSLTC node iterators
Contents
This document describes the function of XSLTC's node iterators. It also
describes the NodeIterator interface and some implementations of
this interface are described in detail:
Node Iterator Function
Node iterators have several functions in XSLTC. The most obvious is
acting as a placeholder for node-sets. Node iterators also act as a link
between the translet and the DOM(s), they can act as filters (implementing
predicates), they contain the functionality necessary to cover all XPath
axes and they even serve as a front-end to XSLTC's node-indexing mechanism
(for the id() and key() functions).
Node Iterator Interface
The node iterator interface is defined in
org.apache.xalan.xsltc.NodeIterator.
The most basic operations in the NodeIterator interface are
for setting the iterators start-node. The "start-node" is
an index into the DOM. This index, and the axis of the iterator, determine
the node-set that the iterator contains. The axis is programmed into the
various node iterator implementations, while the start-node can be set by
calling:
public NodeIterator setStartNode(int node);
Once the start node is set the node-set can be traversed by a sequence of calls to:
public int next();
This method will return the constant NodeIterator.END when
the whole node-set has been returned. The iterator can be reset to the start
of the node-set by calling:
public NodeIterator reset();
Two additional methods are provided to set the position within the node-set. The first method below will mark the current node in the node-set, while the second will (at any point) set the iterators position back to that node.
public void setMark();
public void gotoMark();
Every node iterator implements two functions that make up the
functionality behind XPath's getPosition() and
getLast() functions.
public int getPosition();
public int getLast();
The getLast() function returns the number of nodes in the
set, while the getPosition() returns the current position
within the node-set. The value returned by getPosition() for
the first node in the set is always 1 (one), and the value returned for the
last node in the set is always the same value as is returned by
getLast().
All node iterators that implement an XPath axis will return the node-set in the natural order of the axis. For example, the iterator implementing the ancestor axis will return nodes in reverse document order (bottom to top), while the iterator implementing the descendant will return nodes in document order. The node iterator interface has a method that can be used to determine if an iterator returns nodes in reverse document order:
public boolean isReverse();
Two methods are provided for when node iterators are encapsulated inside a variable or parameter. To understand the purpose behind these two methods we should have a look at a sample XML document and stylesheet first:
<?xml version="1.0"?>
<foo>
<bar>
<baz>A</baz>
<baz>B</baz>
</bar>
<bar>
<baz>C</baz>
<baz>D</baz>
</bar>
</foo>
<xsl:stylesheet version="1.0" xmlns:xsl="http://www.w3.org/1999/XSL/Transform">
<xsl:template match="foo">
<xsl:variable name="my-nodes" select="//foo/bar/baz"/>
<xsl:for-each select="bar">
<xsl:for-each select="baz">
<xsl:value-of select="."/>
</xsl:for-each>
<xsl:for-each select="$my-nodes">
<xsl:value-of select="."/>
</xsl:for-each>
</xsl:for-each>
</xsl:template>
</xsl:stylesheet>
Now, there are three iterators at work here. The first iterator is the
one that is wrapped inside the variable my-nodes - this
iterator contains all <baz/> elements in the
document. The second iterator contains all <bar>
elements under the current element (this is the iterator used by the
outer for-each loop). The third and last iterator is the one
used by the first of the inner for-each loops. When the outer
loop is run the first time, this third iterator will be initialized to
contain the first two <baz> elements under the context
node (the first <bar> element). Iterators are by default
restarted from the current node when used inside a for-each
loop like this. But what about the iterator inside the variable
my-nodes? The variable should keep its assigned value, no
matter what the context node is. In able to prevent the iterator from being
reset, we must use a mechanism to block calls to the
setStartNode() method. This is done in three steps:
- The iterator is created and initialized when the variable gets assigned its value (node-set).
- When the variable is read, the iterator is copied (cloned). The original iterator inside the variable is never used directly. This is to make sure that the iterator inside the variable is always in its original state when read.
- The iterator clone is marked as not restartable to prevent it from
being restarted when used to iterate the
<xsl:for-each>element loop.
These are the two methods used for the three steps above:
public NodeIterator cloneIterator();
public void setRestartable(boolean isRestartable);
Special care must be taken when implementing these methods in some
iterators. The StepIterator class is the best example of this.
This iterator wraps two other iterators; one of which is used to generate
start-nodes for the other - so one of the encapsulated node iterators must
always remain restartable - even when used inside variables. The
StepIterator class is described in detail later in this
document.
Node Iterator Base Class
A node iterator base class is provided to contain some common functionality. The base class implements the node iterator interface, and has a few additional methods:
public NodeIterator includeSelf();
protected final int returnNode(final int node);
protected final NodeIterator resetPosition();
The includeSelf() is used with certain axis iterators that
implement both the ancestor and ancestor-or-self
axis and similar. One common implementation is used for these axes and
this method is used to signal that the "self" node should
also be included in the node-set.
The returnNode() method is called by the implementation of
the next() method. returnNode() increments an
internal node counter/cursor that keeps track of the current position within
the node set. This counter/cursor is then used by the
getPosition() implementation to return the current position.
The node cursor can be reset by calling resetPosition(). This
method is normally called by an iterator's reset() method.
Node Iterator Implementation Details
Axis iterators
All axis iterators are implemented as inner classes of the internal
DOM implementation org.apache.xalan.xsltc.dom.DOMImpl. In this
way all axis iterator classes have direct access to the internal node
type- and navigation arrays of the DOM:
private short[] _type; // Node types
private short[] _namespace; // Namespace URI types
private short[] _prefix; // Namespace prefix types
private int[] _parent; // Index of a node's parent
private int[] _nextSibling; // Index of a node's next sibling node
private int[] _offsetOrChild; // Index of an elements first child node
private int[] _lengthOrAttr; // Index of an elements first attribute node
The axis iterators can be instanciated by calling either of these two methods of the DOM:
public NodeIterator getAxisIterator(final int axis);
public NodeIterator getTypedAxisIterator(final int axis, final int type);
StepIterator
The StepIterator is used to chain other iterators. A
very basic example is this XPath expression:
<xsl:for-each select="foo/bar">
To generate the appropriate node-set for this loop we need three
iterators. The compiler will generate code that first creates a typed axis
iterator; the axis will be child and the type will be that assigned
to <foo> elements. Then a second typed axis iterator will
be created; this also a child -iterator, but this one with the type
assigned to <bar> elements. The third iterator is a
step iterator that encapsulates the two axis iterators. The step iterator is
the initialized with the context node.
The step iterator will use the first axis iterator to generate
start-nodes for the second axis iterator. In plain english this means that
the step iterator will scan all foo elements for any
bar child elements. When a StepIterator is
initialized with a start-node it passes the start node to the
setStartNode() method of its source -iterator (left).
It then calls next() on that iterator to get the start-node
for the iterator iterator (right):
// Set start node for left-hand iterator...
_source.setStartNode(_startNode);
// ... and get start node for right-hand iterator from left-hand,
_iterator.setStartNode(_source.next());
The step iterator will keep returning nodes from its right iterator until
it runs out of nodes. Then a new start-node is retrieved by again calling
next() on the source -iterator. This is why the
right-hand iterator always has to be restartable - even if the step iterator
is placed inside a variable or parameter. This becomes even more complicated
for step iterators that encapsulate other step iterators. We'll make our
previous example a bit more interesting:
<xsl:for-each select="foo/bar[@name='cat and cage']/baz">
This will result in an iterator-tree similar to this:
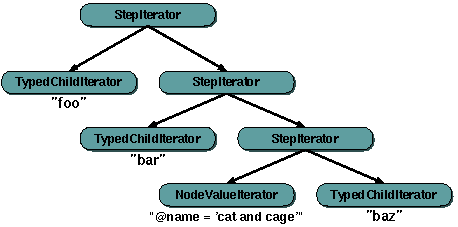
Figure 1: Stacked step iterators
The "foo" iterator is used to supply the second step iterator with start nodes. The second step iterator will pass these start nodes to the "bar" iterator, which will be used to get the start nodes for the third step iterator, and so on....
Iterators for Filtering/Predicates
The org.apache.xalan.xsltc.dom package contains a few
iterators that are used to implement predicates and filters. Such iterators
are normally placed on top of another iterator, and return only those nodes
that match a specific node value, position, etc.
These iterators include:
- NthIterator
- NodeValueIterator
- FilteredStepIterator
- CurrentNodeListIterator
The last one is the most interesting. This iterator is used to implement chained predicates, such as:
<xsl:value-of select="foo[@blob='boo'][2]">
The first predicate reduces the node set from containing all
<foo> elements, to containing only those elements that
have a "blob" attribute with the value 'boo'. The
CurrentNodeListIterator is used to contain this reduced
node-set. The iterator is constructed by passing it a source iterator (in
this case an iterator that contains all <foo> elements)
and a filter that implements the predicate (@blob = 'boo').
SortingIterator
The sorting iterator is one of the main functional components behind the
implementation of the <xsl:sort> element. This element,
including the sorting iterator, is described in detail in the
<xsl:sort>
design document.
SingletonIterator
The singleton iterator is a wrapper for a single node. The node passed
in to the setStartNode() method is the only node that will be
returned by the next() method. The singleton iterator is used
mainly for node to node-set type conversions.
UnionIterator
The union iterator is used to contain unions of node-sets contained in
other iterators. Some of the methods in this iterator are unnecessary
comlicated. The next() method contains an algorithm for
ensuring that the union node-set is returned in document order. We might be
better off by simply wrapping the union iterator inside a duplicate filter
iterator, but there could be some performance implications. Worth checking.
KeyIndex
This is not just an node iterator. An index used for keys and ids will
return a set of nodes that are contained within the named index and that
share a certain property. The KeyIndex implements the node
iterator interface, so that these nodes can be returned and handled just
like any other node set. See the
design document for
<xsl:key>, key() and id()
for further details.