XSLTC and Namespaces
- Functionality
- Namespace overview
- The DOM & namespaces
- Namespaces in the XSL stylesheet
- Namespaces in the output document
Functionality
Namespaces are used when an XML documents has elements have the same
name, but are from different contexts, and thus have different meanings
and interpretations. For instance, a <TITLE> element can
be a HTML title element in one part of the XML document, while it in other
parts of the document the <TITLE> element is used for
encapsulating the title of a play or a book. This sort of confusion is
very common when reading XML source from multiple documents, but can also
occur within a single document.
Namespaces have three very important properties: a name, a prefix (an alias for its name) and a scope. Namespaces are declared as attributes of almost any node in an XML document. The declaration looks like this:
<element xmlns:prefix="http://some.site/spec">....</element>
The "xmlns" tells that this is a namespace declaration. The
scope of the namespace declaration is the element in which it is defined
and all the children of that element.The prefix is the local alias we use
for referencing the namespace, and the URL (it can be anything, really) is
the name/definition of the namespace. Note that even though the namespace
definition is normally an URL, it does not have to point to anything. It
is recommended that it points to a page that describes the elements in the
namespace, but it does not have to. The prefix can be just about anything
- or nothing (in which case it is the default namespace). Any prefix,
including the empty prefix for the default namespace, can be redefined to
refer to a different namespace at any time in an XML document. This is
more likely to happen to the default namespace than any other prefix. Here
is an example of this:
<?xml version="1.0"?>
<employees xmlns:postal="http://postal.ie/spec-1.0"
xmlns:email="http://www.w3c.org/some-spec-3.2">
<employee>
<name>Bob Worker</name>
<postal:address>
<postal:street>Nassau Street</postal:street>
<postal:city>Dublin 3</postal:city>
<postal:country>Ireland</postal:country>
</postal:address>
<email:address>bob.worker@hisjob.ie</email:address>
</employee>
</employees>
This short document has two namespace declarations, one with the prefix
"postal" and another with the prefix "email". The
prefixes are used to distinguish between elements for e-mail addresses and
regular postal addresses. In addition to these two namespaces there is also
an initial (unnamed) default namespace being used for the
<name> and <employee> tags. The scope of the
default namespace is in this case the whole document, while the scope of
the other two declared namespaces is the <employees>
element and its children.
By changing the default namespace we could have made the document a little bit simpler and more readable:
<?xml version="1.0"?>
<employees xmlns:email="http://www.w3c.org/some-spec-3.2">
<employee>
<name>Bob Worker</name>
<address xmlns="http://postal.ie/spec-1.0">
<street>Nassau Street</street>
<city>Dublin 3</city>
<country>Ireland</country>
</address>
<email:address>bob.worker@hisjob.ie</email:address>
</employee>
</employees>
The default namespace is redefined for the <address> node
and its children, so there is no need to specify the street as
<postal:street> - just plain <street> is
sufficient. Note that this also applies to the <address>
where the namespace is first defined. This is in effect a redefinition of
the default namespace.
Namespace overview
Namespaces will have to be handled in three separate parts of the XSLT compiler:
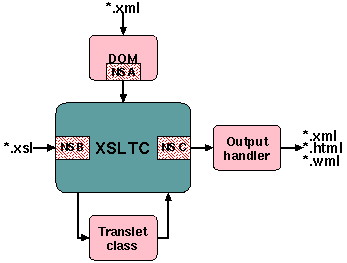
Figure 1: Namespace handlers in the XSLTC
The most obvious is the namespaces in the source XML document (marked "NS A" in figure 1). These namespaces will be handled by our DOM implementation class. The source XSL stylesheet also has its own set of namespaces ("NS B") - one of which is the XSL namespace. These namespaces will be handled at run-time and whatever information that is needed to process there should be compiled into the translet. There is also a set of namespaces that will be used in the resulting document ("NS C"). This is an intersection of the first two. The output document should not contain any more namespace declarations than necessary.
The DOM & namespaces
DOM node types and namespace types
Refer to the XSLTC runtime
environment design document for a description of node types before
proceeding. In short, each node in the our DOM implementation is
represented by a simple integer. By using this integer as an index into an
array called _type[] we can find the type of the node.
The type of the node is an integer representing the type of element the
node is. All elements <bob> will be given the same type,
all text nodes will be given the same type, and so on. By using the node
type as an index an array called _namesArray[] we can find the
name of the element type - in this case "bob". This code fragment shows
how you can, with our current implementation, find the name of a node:
int node = iterator.getNext(); // get next node
int type = _type[node]; // get node type
String name = _namesArray[type]; // get node name
We want to keep the one-type-per-node arrangement, since that lets us
produce fairly efficient code. One type in the DOM maps to one type in
the compiled translet. What we could do to represent the namespace for
each node in the DOM is to add a _namespaceType[] array that holds
namespace types. Each node type maps to a namespace type, and each
namespace type maps to a namespace name (and a prefix with a limited
scope):
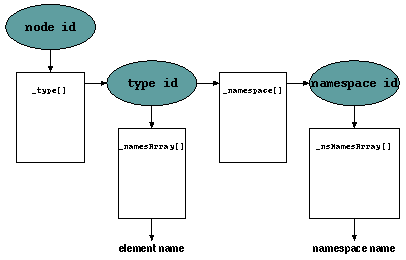
Figure 2: Mapping between node types/names, namespace types/names
This code fragment shows how we could get the namespace name for a node:
int node = iterator.getNext(); // get next node
int type = _type[node]; // get node type
int nstype = _namespace[type]; // get namespace type
String name = _namesArray[type]; // get node element name
String namespace = _nsNamesArray[nstype]; // get node namespace name
Note that namespace prefixes are not included here. Namespace prefixes are local to the XML document and will be expanded to the full namespace names when the nodes are put into the DOM. This, however, is not a trivial matter.
Assigning namespace types to DOM nodes
We cannot simply have a single namespace prefix array similar to the
_namespaceArray[] array for mapping a namespace type to a single
prefix. This because prefixes can refer to different namespaces depending
on where in the document the prefixes are being used. In our last example's
XML fragment the empty prefix ""
initially referred to the default namespace (the one with no name - just
like a Clint Eastwood character). Later on in the document the empty
prefix is changed to refer to a namespace called
"http://postal.ie/spec-1.0".
Namespace prefixes are only relevant at the time when the XML document is parsed and the DOM is built. Once we have the DOM completed we only need a table that maps each node type to a namespace type, and another array of all the names of the different namespaces. So what we want to end up with is something like this:
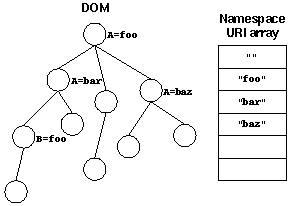
Figure 3: Each namespace references in the DOM gets one entry
The namespace table has one entry for each namespace, nomatter how many prefixes were used ro reference this namespace in the DOM. To build this array we need a temporary data structure used by the DOM builder. This structure is a hashtable - where the various prefixes are used for the hash values. The contents of each entry in the table will be a small stack where previous meanings of each prefix will be stored:

Figure 4: Temporary data structure used by the DOM builder
When the first node is encountered we define a new namespace
"foo" and assign this namespace type/index 1 (the default
namespace "" has index 0). At the same time we use the prefix
"A" for a lookup in the hashtable. This gives us
an integer stack used for the prefix "A". We push the namespace
type 1 on this stack. From now on, until "A" is pop'ed off this
stack, the prefix "A" will map to namespace type 1, which
represents the namespace URI "foo".
We then encounter the next node with a new namespace definition with
the same namespace prefix, we create a new namespace "bar" and
we put that in the namespace table under type 2. Again we use the prefix
"A" as an entry into the namespace prefix table and we get the
same integer stack. We now push namespace type 2 on the stack, so that
namespace prefix "A" maps to namespace URI "bar". When
we have traversed this node's children we need to pop the integer off the
stack, so when we're back at the first node the prefix "A" again
will point to namespace type 0, which maps to "foo". To keep
track of what nodes had what namespace declarations, we use a namespace
declaration stack:
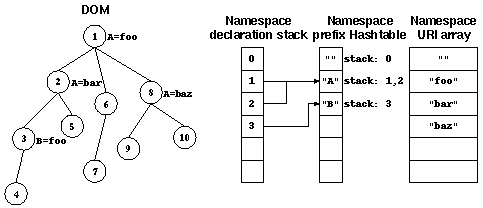
Figure 5: Namespace declaration stack
Every namespace declaration is pushed on the namespace declaration
stack. This stack holds the node index for where the namespace was
declared, and a reference to the prefix stack for this declaration.
The endElement() method of the DOMBuilder class will need to
remove namespace declaration for the node that is closed. This is done
by first checking the namespace declaration stack for any namespaces
declared by this node. If any declarations are found these are un-declared
by poping the namespace prefixes off the respective prefix stack(s), and
then poping the entry/entries for this node off the namespace declaration
stack.
The endDocument() method will build an array that contains
all namespaces used in the source XML document - _nsNamesArray[]
- which holds the URIs of all refered namespaces. This method also builds
an array that maps all DOM node types to namespace types. This two arrays
are accessed through two new methods in the DOM interface:
public String getNamespaceName(int node);
public int getNamespaceType(int node);
Namespaces in the XSL stylesheet
- Storing and accessing namespace information
- Mapping DOM namespaces to stylesheet namespaces
- Wildcards and namespaces
Storing and accessing namespace information
The SymbolTable class has three datastructures that are used to hold namespace information:
-
First there is the
_namespaces[]Hashtable that maps the names of in-scope namespace to their respective prefixes. Each key in the Hashtable object has a stack. A new prefix is pushed on the stack for each new declaration of a namespace. -
Then there is the
_prefixes[]Hashtable. This has the reverse function of the_namespaces[]Hashtable - it maps from prefixes to namespaces. -
There is also a hashtable that is used for implementing the
<xsl:namespace-alias>element. The keys in this hashtable is taken from thestylesheet-prefixattribute of this element, and the resulting prefix (from theresult-prefixattribute) is used as the value for each key.
The SymbolTable class offers 4 methods for accessing these data structures:
public void pushNamespace(String prefix, String uri);
public void popNamespace(String prefix);
public String lookupPrefix(String uri);
public String lookupNamespace(String prefix);
These methods are wrapped by two methods in the Parser class (a Parser object alwas has a SymbolTable object):
// This method pushes all namespaces declared within a single element
public void pushNamespaces(ElementEx element);
// This method pops all namespaces declared within a single element
public void popNamespaces(ElementEx element);
The translet class has, just like the DOM, a namesArray[]
structure for holding the expanded QNames of all accessed elements. The
compiled translet fills this array in its constructor. When the translet
has built the DOM (a DOMImpl object), it passes the DOM to the a DOM
adapter (a DOMAdapter object) together with the names array. The DOM
adapter then maps the translet's types to the DOM's types.
Mapping DOM namespaces and stylesheet namespaces
Each entry in the DOM's _namesArray[] is expanded to contain
the full QName, so that instead of containing prefix:localname it
will now contain namespace-uri:localname. In this way the expanded
QName in the translet will match the exanded QName in the DOM. This assures
matches on full QNames, but does not do much for match="A:*" type
XPath patterns. This is where our main challenge lies.
Wildcards and namespaces
The original implementation of the XSLTC runtime environment would
only allow matches on "*" and "@*" patterns. This was
achieved by mapping all elements that could not be mapped to a translet
type to 3 (DOM.ELEMENT type), and similarly all unknown attributes to
type 4 (DOM.ATTRIBUTE type). The main switch() statement in
applyTemplates() would then have a separate "case()"
for each of these. (Under each case() you might have to check
for the node's parents in case you were matching on "path/*"-type
patterns.) This figure shows how that was done:
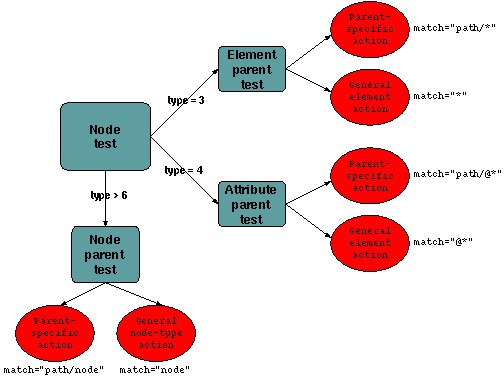
Figure 6: Previous pattern matching
The "Node test" box here represents the "switch()" statement.
The "Node parent test" box represent each "case:" for that
switch() statement. There is one case: for each know
translet node type. For each node type we have to check for any parent
patterns - for instance, for the pattern "/foo/bar/baz", we will
get a match with case "baz", and we have to check that the parent
node is "bar" and that the grandparent is "foo" before
we can say that we have a hit. The "Element parent test" is the test that
is done all DOM nodes that do not directly match any translet types. This
is the test for "*" or "foo/*". Similarly we have a
"case:" for match on attributes ("@*").
What we now want to achieve is to insert a check for patterns on the
format "ns:*", "foo/ns:*" or "ns:@*", which
this figure illustrates:
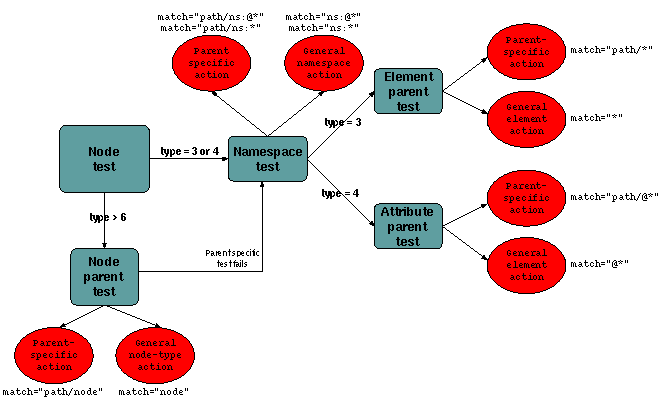
Figure 7: Pattern matching with namespace tests
Each node in the DOM needs a namespace type as well as the QName type.
With this type we can match wildcard rules to any specific namespace.
So after any checks have been done on the whole QName of a node (the type),
we can match on the namespace type of the node. The main dispatch
switch() in applyTemplates() must be changed from this:
public void applyTemplates(DOM dom, NodeIterator iterator,
TransletOutputHandler handler) {
// Get next node from iterator
while ((node = iterator.next()) != END) {
// Get internal node type
final int type = DOM.getType(node);
switch(type) {
case DOM.ROOT: // Match on "/" pattern
handleRootNode();
break;
case DOM.TEXT: // Handle text nodes
handleText();
break;
case DOM.ELEMENT: // Match on "*" pattern
handleWildcardElement();
break;
case DOM.ATTRIBUTE: // Handle on "@*" pattern
handleWildcardElement();
break;
case nodeType1: // Handle 1st known element type
compiledCodeForType1();
break;
:
:
:
case nodeTypeN: // Handle nth known element type
compiledCodeForTypeN();
break;
default:
NodeIterator newIterator = DOM.getChildren(node);
applyTemplates(DOM, newIterator, handler);
break;
}
}
return;
}
To something like this:
public void applyTemplates(DOM dom, NodeIterator iterator,
TransletOutputHandler handler) {
// Get next node from iterator
while ((node = iterator.next()) != END) {
// First run check on node type
final int type = DOM.getType(node);
switch(type) {
case DOM.ROOT: // Match on "/" pattern
handleRootNode();
continue;
case DOM.TEXT: // Handle text nodes
handleText();
continue;
case DOM.ELEMENT: // Not handled here!!!
break;
case DOM.ATTRIBUTE: // Not handled here!!!
break;
case nodeType1: // Handle 1st known element type
if (compiledCodeForType1() == match) continue;
break;
:
:
:
case nodeTypeN: // Handle nth known element type
if (compiledCodeForTypeN() == match) continue;
break;
default:
break;
}
// Then run check on namespace type
final int namespace = DOM.getNamespace(type);
switch(namespace) {
case 0: // Handle nodes matching 1st known namespace
if (handleThisNamespace() == match) continue;
break;
case 1: // Handle nodes matching 2nd known namespace
if (handleOtherNamespace() == match) continue;
break;
}
// Finally check on element/attribute wildcard
if (type == DOM.ELEMENT) {
if (handleWildcardElement() == match)
continue;
else {
// The default action for elements
NodeIterator newIterator = DOM.getChildren(node);
applyTemplates(DOM, newIterator, handler);
}
}
else if (type == DOM.ATTRIBUTE) {
handleWildcardAttribute();
continue;
}
}
}
First note that the default action (iterate on children) does not hold for attributes, since attribute nodes do not have children. Then note that the way the three levels of tests are ordered is consistent with the way patterns should be prioritised:
- Match on element/attribute types:
-
match="/"- match on the root node -
match="B"- match on any B element -
match="A/B"- match on B elements with A parent -
match="A | B"- match on B or A element -
match="foo:B"- match on B element within "foo" namespace - Match on namespace:
-
match="foo:*"- match on any element within "foo" namespace -
match="foo:@*"- match on any attribute within "foo" namespace -
match="A/foo:*"- match on any element within "foo" namespace with A parent -
match="A/foo:@*"- match on any attribute within "foo" namespace with A parent - Match on wildcard:
-
match="*"- match on any element -
match="@*"- match on any attribute -
match="A/*"- match on any element with A parent -
match="A/@*"- match on any attribute with A parent
Namespaces in the output document
These are the categories of namespaces that end up in the output document:
- Namespaces used in literal elements/attributes in the stylesheet. These namespaces should be declared once before use in the output document. These elements are copied to the output document independent of namespaces in the input XML document. However, the namespaces can be declared using the same prefix, such that a namespace used by a literal result element can overshadow a namespace from the DOM.
- Namespaces from elements in the stylesheet that match elements in the DOM. No namespaces from the DOM should be copied to the output document unless they are actually referenced in the stylesheet. No namespaces from the stylesheet should be copied to the output document unless the elements in which they are references match elements in the DOM.
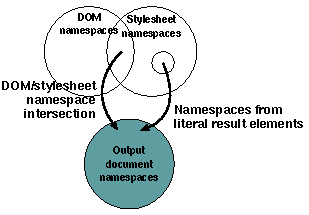
Figure 8: Namespace declaration in the output document
Any literal element that ends up in the output document must declare all
namespaces that were declared in the <xsl:stylesheet<
element. Exceptions are namespaces that are listed in this element's
exclude-result-prefixes or extension-element-prefixes
attributes. These namespaces should only be declared if they are referenced
in the output.
Literal elements should only declare namespaces when necessary. A
literal element should only declare a namespace in the case where it
references a namespace using prefix that is not in scope for this
namespace. The output handler will take care of this problem. All namespace
declarations are put in the output document using the output handler's
declarenamespace() method. This method will monitor all namespace
declarations and make sure that no unnecessary declarations are output.
The datastructures used for this are similar to those used to track
namespaces in the XSL stylesheet:
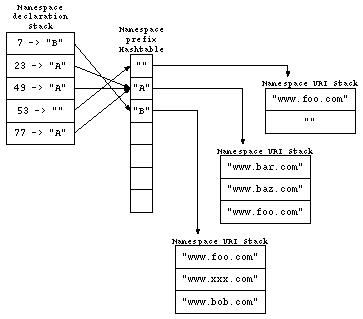
Figure 9: Handling Namespace declarations in the output document