XSLTC Internal DOM
- General functionlaity
- Components of the internal DOM
- Internal structure
- Tree navigation
- Namespaces
- W3C DOM2 navigation support
- The DOM adapter - DOMAdapter
- The DOM multiplexer - MultiDOM
- The DOM builder - DOMImpl$DOMBuilder
General functionality
The internal DOM gives the translet access to the XML document(s) it has to transform. The interface to the internal DOM is specified in the DOM.java class. This is the interface that the translet uses to access the DOM. There is also an interface specified for DOM caches -- DOMCache.java
Components of the internal DOM
This DOM interface is implemented by three classes:
-
org.apache.xalan.xsltc.dom.DOMImpl
This is the main DOM class. An instance of this class contains the nodes of a single XML document.
-
org.apache.xalan.xsltc.dom.MultiDOM
This class is best described as a DOM multiplexer. XSLTC was initially designed to operate on a single XML document, and the initial DOM and the DOM interface were designed and implemented without thedocument()function in mind. This class will allow a translet to access multiple DOMs through the original DOM interface.
-
org.apache.xalan.xsltc.dom.DOMAdapter
The DOM adapter is a mediator between a DOMImpl or a MultiDOM object and a single translet. A DOMAdapter object contains mappings and reverse mappings between node types in the DOM(s) and node types in the translet. This mediator is needed to allow several translets access to a single DOM.
-
org.apache.xalan.xsltc.dom.DocumentCache
A sample DOM cache (implementing DOMCache) that is used with our sample transformation applications.
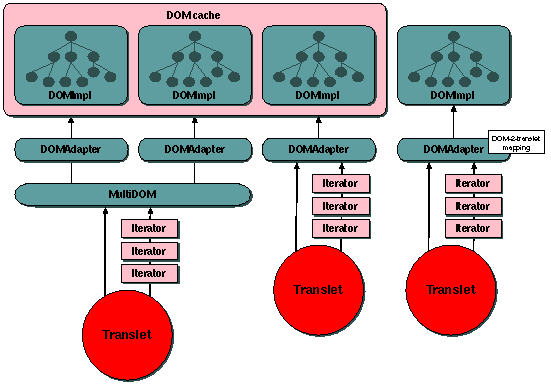
Figure 1: Main components of the internal DOM
The figure above shows how several translets can access one or more
internal DOM from a shared pool of cached DOMs. A translet can also access a
DOM tree outside of a cache. The Stylesheet class that represents the XSL
stylesheet to compile contains a flag that indicates if the translet uses the
document() function. The code compiled into the translet will act
accordingly and instanciate a MultiDOM object if needed (this code is compiled
in the compiler's Stylesheet.compileTransform() method).
Internal Structure
- Node identification
- Element nodes
- Attribute nodes
- Text nodes
- Comment nodes
- Processing instructions
Node identifation
Each node in the DOM is represented by an integer. This integer is an
index into a series of arrays that describes the node. Most important is
the _type[] array, which holds the (DOM internal) node type. There
are some general node types that are described in the DOM.java interface:
public final static int ROOT = 0;
public final static int TEXT = 1;
public final static int UNUSED = 2;
public final static int ELEMENT = 3;
public final static int ATTRIBUTE = 4;
public final static int PROCESSING_INSTRUCTION = 5;
public final static int COMMENT = 6;
public final static int NTYPES = 7;
Element and attribute nodes will be assigned types based on their expanded
QNames. The _type[] array is used for this:
int type = _type[node]; // get node type
The node type can be used to look up the element/attribute name in the
element/attribute name array _namesArray[]:
String name = _namesArray[type-NTYPES]; // get node element name
The resulting string contains the full, expanded QName of the element or attribute. Retrieving the namespace URI of an element/attribute is done in a very similar fashion:
int nstype = _namespace[type-NTYPES]; // get namespace type
String namespace = _nsNamesArray[nstype]; // get node namespace name
Element nodes
The contents of an element node (child nodes) can be identified using
the _offsetOrChild[] and _nextSibling[] arrays. The
_offsetOrChild[] array will give you the first child of an element
node:
int child = _offsetOrChild[node]; // first child
child = _nextSibling[child]; // next child
The last child will have a "_nextSibling[]" of 0 (zero).
This value is OK since the root node (the 0 node) will not be a child of
any element.
Attribute nodes
The first attribute node of an element is found by a lookup in the
_lengthOrAttr[] array using the node index:
int attribute = _offsetOrChild[node]; // first attribute
attribute = _nextSibling[attribute]; // next attribute
The names of attributes are contained in the _namesArray[] just
like the names of element nodes. The value of attributes are store the same
way as text nodes:
int offset = _offsetOrChild[attribute]; // offset into character array
int length = _lengthOrAttr[attribute]; // length of attribute value
String value = new String(_text, offset, length);
Text nodes
Text nodes are stored identically to attribute values. See the previous section on attribute nodes.
Comment nodes
The internal DOM does currently not contain comment nodes. Yes, I am quite aware that the DOM has a type assigned to comment nodes, but comments are still not inserted into the DOM.
Processing instructions
Processing instructions are handled as text nodes. These nodes are stored identically to attribute values. See the previous section on attribute nodes.
Tree navigation
The DOM implementation contains a series of iterator that implement the
XPath axis. All these iterators implement the NodeIterator interface and
extend the NodeIteratorBase base class. These iterators do the job of
navigating the tree using the _offsetOrChild[], _nextSibling
and _parent[] arrays. All iterators that handles XPath axis are
implemented as a private inner class of DOMImpl. The translet uses a handful
of methods to instanciate these iterators:
public NodeIterator getIterator();
public NodeIterator getChildren(final int node);
public NodeIterator getTypedChildren(final int type);
public NodeIterator getAxisIterator(final int axis);
public NodeIterator getTypedAxisIterator(final int axis, final int type);
public NodeIterator getNthDescendant(int node, int n);
public NodeIterator getNamespaceAxisIterator(final int axis, final int ns);
public NodeIterator orderNodes(NodeIterator source, int node);
There are a few iterators in addition to these, such as sorting/ordering iterators and filtering iterators. These iterators are implemented in separate classes and can be instanciated directly by the translet.
Namespaces
Namespace support was added to the internal DOM at a late stage, and the design and implementation of the DOM bears a few scars because of this. There is a separate design document that covers namespaces.
W3C DOM2 navigation support
The DOM has a few methods that give basic W3C-type DOM navigation. These methods are:
public Node makeNode(int index);
public Node makeNode(NodeIterator iter);
public NodeList makeNodeList(int index);
public NodeList makeNodeList(NodeIterator iter);
These methods return instances of inner classes of the DOM that implement the W3C Node and NodeList interfaces.
The DOM adapter - DOMAdapter
Translet/DOM type mapping
The DOMAdapter class performs the mappings between DOM and translet node types, and vice versa. These mappings are necessary in order for the translet to correctly identify an element/attribute in the DOM and for the DOM to correctly identify the element/attribute type of a typed iterator requested by the translet. Note that the DOMAdapter also maps translet namespace types to DOM namespace types, and vice versa.
The DOMAdapter class has four global tables that hold the translet/DOM
type and namespace-type mappings. If the DOM knows an element as type
19, the DOMAdapter will translate this to some other integer using the
_mapping[] array:
int domType = _mapping[transletType];
This action will be performed when the DOM asks what type a specific node
is. The reverse is done then the translet wants an iterator for a specific
node type. The DOMAdapter must translate the translet-type to the type used
internally in the DOM by looking up the _reverse[] array:
int transletType = _mapping[domType];
There are two additional mapping tables: _NSmapping[] and
_NSreverse[] that do the same for namespace types.
Whitespace text-node stripping
The DOMAdapter class has the additional function of stripping whitespace nodes in the DOM. This functionality had to be put in the DOMAdapter, as different translets will have different preferences for node stripping.
Method mapping
The DOMAdapter class implements the same DOM interface as the
DOMImpl class. A DOMAdapter object will look like a DOMImpl tree, but the
translet can access it directly without being concerned with type mapping
and whitespace stripping. The getTypedChildren() demonstrates very
well how this is done:
public NodeIterator getTypedChildren(int type) {
// Get the DOM type for the requested typed iterator
final int domType = _reverse[type];
// Now get the typed child iterator from the DOMImpl object
NodeIterator iterator = _domImpl.getTypedChildren(domType);
// Wrap the iterator in a WS stripping iterator if child-nodes are text nodes
if ((domType == DOM.TEXT) && (_filter != null))
iterator = _domImpl.strippingIterator(iterator,_mapping,_filter);
return(iterator);
}
The DOM multiplexer - MultiDOM
The DOM multiplexer class is only used when the compiled stylesheet uses
the document() function. An instance of the MultiDOM class also
implements the DOM interface, so that it can be accessed in the same way
as a DOMAdapter object.
A node in the DOM is identified by an integer. The first 8 bits of this integer are used to identify the DOM in which the node belongs, while the lower 24 bits are used to identify the node within the DOM:
| 31-24 | 23-16 | 16-8 | 7-0 |
| DOM id | node id | ||
The DOM multiplexer has an array of DOMAdapter objects. The topmost 8 bits of the identifier is used to find the correct DOM from the array. Then the lower 24 bits are used in calls to methods in the DOMAdapter object:
public int getParent(int node) {
return _adapters[node>>>24].getParent(node & 0x00ffffff) | node & 0xff000000;
}
Note that the node identifier returned by this method has the same upper 8
bits as the input node. This is why we OR the result from
DOMAdapter.getParent() with the top 8 bits of the input node.
The DOM builder - DOMImpl$DOMBuilder
- startElement()
- endElement()
- startPrefixMapping()
- endPrefixMapping()
- characters()
- startDocument()
- endDocument()
The DOM builder is an inner class of the DOM implementation. The builder
implements the SAX2 ContentHandler interface and populates the DOM
by receiving SAX2 events from a SAX2 parser (presently xerces). An instance
of the DOM builder class can be retrieved from DOMImpl.getBuilder()
method, and this handler can be set as an XMLReader's content handler:
final SAXParserFactory factory = SAXParserFactory.newInstance();
final SAXParser parser = factory.newSAXParser();
final XMLReader reader = parser.getXMLReader();
final DOMImpl dom = new DOMImpl();
reader.setContentHandler(dom.getBuilder());
The DOM builder will start to populate the DOM once the XML parser starts generating SAX2 events:
startElement()
This method can be called in one of two ways; either with the expanded
QName (the element's separate uri and local name are supplied) or as a
normal QName (one String on the format prefix:local-name). The DOM stores
elements as expanded QNames so it needs to know the element's namespace URI.
Since the URI is not supplied with this call, we have to keep track of
namespace prefix/uri mappings while we're building the DOM. See
startPrefixMapping()
below for details on
namespace handling.
The startElement() inserts the element as a child of the current
parent element, creates attribute nodes for all attributes in the supplied
"Attributes" attribute list (by a series of calls to
makeAttributeNode()), and finally creates the actual element node
(by calling internElement(), which inserts a new entry in the
_type[] array).
endElement()
This method does some cleanup after the startElement() method,
such as revering xml:space settings and linking the element's
child nodes.
startPrefixMapping()
This method is called for each namespace declaration in the source
document. The parser should call this method before the prefix is referenced
in a QName that is passed to the startElement() call. Namespace
prefix/uri mappings are stored in a Hashtable structure. Namespace prefixes
are used as the keys in the Hashtable, and each key maps to a Stack that
contains the various URIs that the prefix maps to. The URI on top of the
stack is the URI that the prefix currently maps to.

Figure 2: Namespace handling in the DOM builder
Each call to startPrefixMapping() results in a lookup in the
Hashtable (using the prefix), and a push() of the URI onto the
Stack that the prefix maps to.
endPrefixMapping()
A namespace prefix/uri mapping is closed by locating the Stack for the
prefix, and then pop()'ing the topmost URI off this Stack.
characters()
Text nodes are stored as simple character sequences in the character array
_text[]. The start and lenght of a node's text can be determined by
using the node index to look up _offsetOrChild[] and
_lengthOrAttribute[].
We want to re-use character sequences if two or more text nodes have
identical content. This can be achieved by having two different text node
indexes map to the same character sequence. The maybeReuseText()
method is always called before a new character string is stored in the
_text[] array. This method will locate the offset of an existing
instance of a character sequence.
startDocument()
This method initialises a bunch of data structures that are used by the
builder. It also pushes the default namespace on the namespace stack (so that
the "" prefix maps to the null namespace).
endDocument()
This method builds the _namesArray[], _namespace[]
and _nsNamesArray[] structures from temporary datastructures used
in the DOM builder.